|
Компания Intel опубликовала наработки проекта nGraph, в рамках которого развивается открытый компилятор, набор библиотек и runtime для компиляции в исполняемый код моделей глубинного машинного обучения, подготовленных при помощи различных фреймворков. Код проекта написан на языке С++ и распространяется под лицензией Apache 2.0.
nGraph позволяет экспериментировать и создавать прототипы систем машинного обучения не привязываясь к конкретному фреймворку и не заботясь о том, как адаптировать подготовленные модели нейронной сети
к тренировке и эффективному выполнению на различных классах устройств. В настоящее время в nGraph реализована прямая поддержка компиляции моделей, подготовленных для фреймворков TensorFlow, Apache MXNet и Neon (Intel Nervana), а также косвенная поддержка моделей Caffe2, PyTorch и CNTK (Cognitive Toolkit), которая обеспечивается через промежуточное преобразование в универсальный формат ONNX (Open Neural Network Exchange).
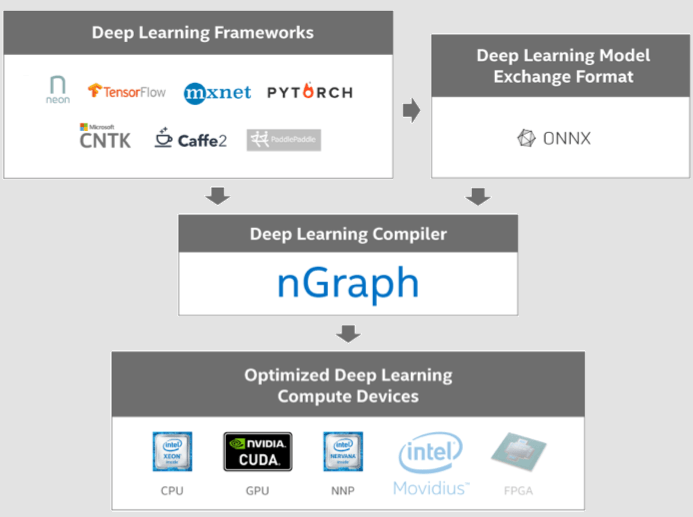
На выходе может формироваться оптимизированный машинный код, готовый для исполнения на системах на основе архитектуры Intel (x86, Intel Xeon, Xeon Phi), на GPU (NVIDIA CUDA) и на специализированных процессорах Intel NNP (Nervana Neural Network Processor). В ближайшее время ожидается поддержка FPGA и чипов Movidius. nGraph пытается избавить разработчиков от необходимости выполнения трудоёмких задач по оптимизации модели для конкретного типа устройств, ограничивающих область применения и усложняющих портирование на новые устройства.
Предоставляемое в nGraph промежуточное представление графа вычислений (nGraph IR) абстрагирует детали реализации конкретных устройств и даёт возможность разработчику сосредоточится на научной работе, алгоритмах и моделях, не заботясь о формировании оптимального машинного кода. Каждый узел или операция в данном графе представляют один шаг вычислений, который производит на выходе ноль или несколько тензоров (многомерные массивы данных) на основе нуля или более тензоров на входе.
Каждая операция nGraph IR является сборочным блоком, из которых можно скомпоновать более сложные операции, предоставляемые различными фреймворками машинного обучения. Для каждого фреймворка подготовлена обвязка, которая транслирует модели со специфичными операторами в унифицированное промежуточное представление nGraph. При формировании машинного кода абстрактная функциональность устройств преобразуется в комбинацию общих и специфичных для конкретных устройств преобразований над графом.
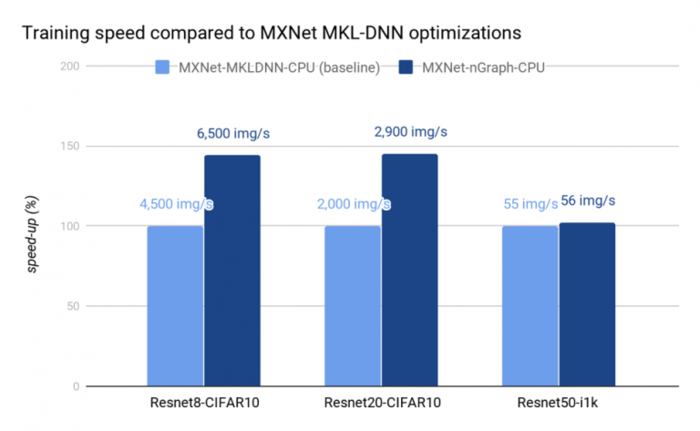
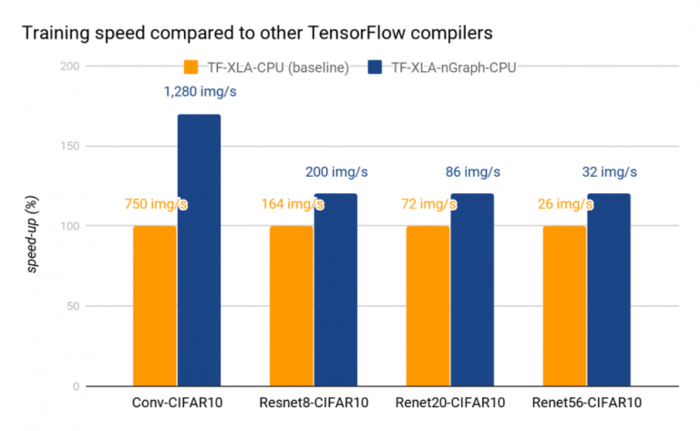
По сравнению со штатными компиляторами MKLDNN (MXNet) и TensorFlow XLA, в nGraph задействованы дополнительные оптимизации для процессоров Intel и других целевых платформ. Например, при тестировании производительности тренировки модели на системе с CPU Intel Xeon Platinum 8180, прирост производительности в отдельных тестах достигает 30% по сравнению с MKLDNN и 40% по сравнению с TensorFlow XLA.
| 

